Problem Set 9 (beta version)
This pset is ungraded. The exercises are for review purposes.
Unfolding in time
Define a recurrent net by for to with initial condition . At time ,
- is the -dimensional activity vector for the input neurons (input vector),
- is the -dimensional activity vector for the hidden neurons (hidden state vector),
- and is the -dimensional activity vector for the output neurons (output vector).
The network contains three connection matrices:
- The matrix specifies how the hidden neurons are influenced by the input,
- the “transition matrix” governs the dynamics of the hidden neurons,
- and the matrix specifies how the output is “read out” from the hidden neurons.
The network can be depicted as
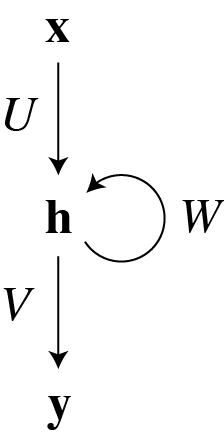
where the recurrent connectivity is represented by the loop. Note that if were zero, this would reduce to a multilayer perceptron with a single hidden layer.
If we want to run the recurrent net for a fixed number of time steps, we can unfold or unroll the loop in the above diagram to yield a feedforward net with the architecture:
In this diagram, we temporarily imagine that the connection matrices , , and vary with time: This reduces to the recurrent net in the case that for all (and similarly for the other connection matrices). This is called “weight sharing through time.”
The diagram has the virtue of making explicit the pathways that produce temporal dependencies. The last output depends on the last input through the short pathway that goes through . The last output also depends on the first input through the long pathway from to .
Backpropagation through time
The backward pass can be depicted as
Here is the backward pass variable that corresponds with the forward pass preactivity (and similarly for other tilde variables).
Exercises
-
Write the equations of the backward pass corresponding to the diagram. As a concrete example, use the loss \[ E = \sum_{t=1}^T \frac{1}{2}|\vec{d}_t - \vec{y}_t|^2 \] where is a vector of desired values for the output neurons at time . The equations for and won’t be used in the gradient descent updates, but write them anyway. (They would be useful if were the output of other neural net layers and we wanted to continue backpropagating through those layers too.)
-
In the gradient descent updates, supply the missing letters where there are question marks. Note how the backward pass diagram above shows the paths by which the loss at time can influence the gradient updates for previous times.
-
To obtain the backprop update for the recurrent net, we must enforce the constraint of weight sharing in time ( for all , etc.). Write the gradient updates for , , and .
Backprop with multiplicative interactions
Consider the feedforward net, The vectors represent the layer activities, and superscripts indicate layer indices. The elementwise multiplication of and makes this net different from a multilayer perceptron.
Exercises
- Write the backward pass for the net.
- Write the gradient updates for the weights and biases.
REINFORCE
Suppose that the probability that a random variable takes on the value is given by the parametrized function ,
I am following the convention that random variables (e.g. ) are written in upper case, while values (e.g. ) are written in lower case.
Given a reward function , define its expected value by
where the sum is over all possible values of the random variable . The expected reward is a function of the parameters . How can we maximize this function?
The REINFORCE algorithm consists of the following steps
- Draw a sample of the random variable .
- Compute the eligibility (for reinforcement)
- Observe the reward .
- Update the parameters via
The basic theorem is that this algorithm is stochastic gradient ascent on the expected reward of Eq. (\ref{eq:ExpectedReward}). To apply the REINFORCE algorithm,
- It is sufficient to observe reward from random samples; no explicit knowledge of the reward function is necessary.
- One must have enough knowledge about to be able to compute the eligibility.
As a special case, suppose that is a state-action pair taking on values . The reward is a function of both state and action, and the probability distribution of state-action pairs is
We interpret the probability \(\prob[S=s]\) as describing the states of the world. The conditional probability \(\log\prob[A=a|S=s]\) describes a stochastic machine that takes the state \(S\) of the world as input and produces action \(A\) as output. So the eligibility is
The first term in the sum vanishes because the parameter does not affect the world. Therefore we can be ignorant of , which is fortunate given that the world is complex. Only the second term in the sum matters, because only affects the stochastic machine. So the eligibility reduces to
We’ve only considered the case in which successive states of the world are drawn independently at random. It turns out that REINFORCE easily generalizes to control of a Markov decision process, in which states of the world have temporal dependences. It also generalizes to partially observable Markov decision processes, in which the stochastic machine has incomplete information about the state of the world.
REINFORCE-backprop
Suppose that the stochastic machine is a neural net with a softmax output. The parameter vector \(\theta\) then refers to the weights and biases. Note that \(\log\prob[A=a|S=s]\) is the same (up to a minus sign) as the loss function used for neural net training, assuming that the desired output is \(a\) (see softmax exercise in Problem Set 1). So \(\nabla_\theta\log\prob[A=a|S=s]\) should be the same as the backprop updates assuming that the desired output is \(a\). The minus sign doesn't matter because here we are performing stochastic gradient ascent rather than stochastic gradient descent. Therefore we can combine REINFORCE and backprop in the following algorithm
- Draw a sample of the random variable (observe the world).
- Feed as input to a neural network with a softmax output.
- Choose a random action by sampling from the softmax probability distribution.
- Pretend that the chosen action is the correct one, and compute the regular backprop updates for the weights and biases.
- Observe the reward .
- Before applying the incremental updates to the weights and biases, multiply the updates by the reward .
Exercises
-
Prove that Eq. (\ref{eq:ThetaUpdate}) is stochastic gradient ascent on the expected reward of Eq. (\ref{eq:ExpectedReward}). In other words, show that the expectation value of the right hand side of Eq. (\ref{eq:ThetaUpdate}) is equal to .
-
Prove that the eligibility of Eq. (\ref{eq:Eligibility}) has zero mean. This means that the eligibility is like a “noise” that is intrinsic to the system. Note that statisticians refer to the eligibility as the score function, which is used to define Fisher information.
-
Prove that the gradient of the expected reward is the covariance of the reward and the eligibility.
-
Consider a multilayer perceptron with a single hidden layer (two layers of connections) and a final softmax output. Write out the REINFORCE-backprop algorithm in full.